AtlantaCrime
Atlanta Crime Mapping for CS7641 - Group 17
Abdurrahmane Rikli, Gabriel Leventhal-Douglas, Kevin Tynes, Aayush Dubey, and Sanjeev Prasada

Introduction
Motivation
In Atlanta, the overall crime rate is 108% higher than the national average. Crime is an ever-present concern. With almost 30 thousand crimes a year and a 61% crime rate per capita, Atlanta is one of the 3% most dangerous cities in the United States [1]. With such issues, the police force cannot deal with crime on a case-by-case basis. They need to be directed to crime-heavy areas preemptively.
What are you trying to do to tackle with your project motivation or problem?
Sufficient patrols in crime-heavy areas can be achieved using a prediction model to estimate the areas with the most severe crimes. More dangerous crimes can be preempted. With a real-time updating machine learning model, the police force can consistently catch up with crimes before they even occur day by day, and more often than not, their presence alone is enough to prevent crimes from occurring. Overall, as long as informative data is fed into the model, average crime rate is sure to consistently drop.
We reviewed literature of machine learning crime prediction methods using spatial [5, 3] and temporal [2] data in conjunction with crime-type. We will build upon this prior work by applying these methods to Atlanta crime data and improving predictive model efficiency.
What have people already done?
Crime statistics -likelihood for the most part- were pridected per 100k people in the state of Mississipi, irrespective of any features aside from the state’s crime type statistics in their paper[2]. For the most part, time and space relevant features were examined only within the context of splitting areas into grids, and predicting intensity and displacement[3], although there were some attempts at clustering crime occurrences [5]. Closest to our approach was an attempt at predicting crime occurrences through similar features using KNN and Boosted Decision Tree, although the accuracy was 44% at its highest[4].
Dataset (Needs description of features, accessability, etc.)
Our dataset comes from the Atlanta PD Crime Statistics dataset publicly available on the Atlanta PD website. This data is available as two separate datasets ‘COBRA-2009-2018’ and ‘COBRA-2019’. After analyzing the Atlanta PD Crime dataset from 2009-2018, the most popular crimes in descending order are larceny from vehicle, larceny non vehicle, burglary at residence, and automobile theft.
Our dataset is record-based; each row in the dataset represents one crime and the features of that crime (represented below in tables). We have a total of 20 features per record and a total of 317,905 records of crime within the Perimeter of Atlanta. There were a few columns we had to remove due a large number of null’s and a few rows were removed based on inconsistency of data.
Using our initial record-based dataset, we created count-based datasets to enable us to predict number of crimes that will occur on each day and in each neighborhood. For these datasets, our target features for our supervised models were counts in each crime severity category, and an associated crime score based on these counts.
Original Dataset
| Report Number | Report Date | Occur Date | Occur Time | Possible Date | Possible Time | Beat | Apartment Office Prefix | Apartment Number | Location | Shift Occurence | Location Type | UCR Literal | UCR # | IBR Code | Neighborhood | NPU | Latitude | Longitude |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 090010930 | 2009-01-01 | 2009-01-01 | 1145 | 2009-01-01 | 1148 | 408 | 2841 GREENBRIAR PKWY | Day Watch | 8 | LARCENY-NON VEHICLE | 0630 | 2303 | Greenbriar | R | 33.688450000000003 | -84.493279999999999 | ||
| 090011083 | 2009-01-01 | 2009-01-01 | 1330 | 2009-01-01 | 1330 | 506 | 12 BROAD ST SW | Day Watch | 9 | LARCENY-NON VEHICLE | 0630 | 2303 | Downtown | M | 33.7532 | -84.392009999999999 | ||
| 090011208 | 2009-01-01 | 2009-01-01 | 1500 | 2009-01-01 | 1520 | 413 | 3500 MARTIN L KING JR DR SW | Unknown | 8 | LARCENY-NON VEHICLE | 0630 | 2303 | Adamsville | H | 33.757350000000002 | -84.50282 | ||
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
Unsupervised algorithms preprocessed dataset
| Occur Date | Occur Time | Day of Week | Month | Day of Month | Year | Latitude | Longitude | Crime Category |
|---|---|---|---|---|---|---|---|---|
| 2009-01-01 | 0745 | 1 | 3 | 23 | 18 | 33.69 | -84.49 | 4 |
| 2009-01-01 | 1030 | 6 | 7 | 4 | 9 | 33.82 | -84.39 | 4 |
| 2009-01-01 | 1615 | 0 | 9 | 16 | 13 | 33.76 | -84.50 | 3 |
| … | … | … | … | … | … | … | … | … |
Supervised algorithms dataset
| Year | Month | Day | Day of Week | Category 1 | Category 2 | Category 3 | Category 4 |
|---|---|---|---|---|---|---|---|
| 2009 | 1 | 1 | 3 | 0 | 15 | 58 | 48 |
| 2009 | 1 | 2 | 4 | 0 | 15 | 46 | 73 |
| 2009 | 1 | 3 | 5 | 1 | 21 | 37 | 56 |
| … | … | … | … | … | … | … | … |
Approach
For our unsupervised learning, we clustered based on both location and time to provide us more insights about the dataset that will be useful in understanding the data prior to building our predictive models with supervised learning algorithms. We also employed dimensionality reduction algorithms to explore the relationship between variables in our dataset’s feature space.
For our supervised learning, we explored various algorithms to help predict crime severity across neighborhoods and time. In our record-based datasets, we employed classification methods to predict crime category of different crime occurrences. In our count-based datasets, we employed regression methods to predict the calculated crime score of different neighborhoods on different days.
Throughout our modeling and data pre-processing, we used primarily Python, along with a few Python packages: sci-kit learn, sci-py, pandas, and numpy.
What is new in our approach?
We generated a crime score for each neighborhood and for each day. This is our “secret sauce”. We believe that in order to label locations as hotspots, we needed to aggregate a score which accounts for severity of different crimes. This feature was created to encapsulate the level of crime in a neighborhood and/or on a given day in a single value. We felt that using this crime score as our predictor feature brought us closer to our use case of helping civilians and the police force be able to determine crime across time and neighborhoods.
We grouped types of crime into four categories based on our research and opinions on the severity of crimes. We then associated a weight to each category, and increased weight by order of 10 for more severe crimes.
| Category | Crimes in Category | Weight |
|---|---|---|
| 1 | homicides, manslaughter | 1000x |
| 2 | aggravated assault, robbery | 100x |
| 3 | burgulary, auto-theft | 10x |
| 4 | larceny | 1x |
Crime score is calculated as a weighted sum of crime category counts in a particular location and time. For example, in 2019, the worst crime score was in ‘Downtown’ with a neighborhood score of 23254.
Crime Score Calculation:




Top 5 Crime Scores:
| Rank | Neighborhood | 2008-2019 Sum | 2019 Sum (YTD) |
|---|---|---|---|
| 1 | Downtown | 366925 | 24984 |
| 2 | Midtown | 188754 | 12283 |
| 3 | West End | 186872 | 9031 |
| 4 | Old Fourth Ward | 182502 | 11441 |
| 5 | Grove Park | 155795 | 9488 |
Bottom 5 Crime Scores:
| Rank | Neighborhood | 2008-2019 Sum | 2019 Sum (YTD) |
|---|---|---|---|
| 200 | Edmund Park | 24 | 10 |
| 199 | Mays | 25 | 10 |
| 198 | Carroll Heights | 31 | 0 |
| 197 | Englewood Manor | 110 | 0 |
| 196 | Horseshoe Community | 129 | 10 |
Visualization
Crime intensities across the city limits of Atlanta.
These figures of Atlanta are from the 2009-2018 dataset, visualizing the total count of crimes that occurred.

These figures of Atlanta visualize the total count of crimes that occurred for each crime-category.

How we created the visualizations:
Shapefiles were sourced from the Atlanta Regional Commission (ARC). They include the information for the shapes and coordinates for the different neighborhoods of Atlanta. The data for crime scores, categories, and neighborhoods was generated using the publicly available crime reports from the Atlanta Police Department website, and imported as a CSV.
Each neighborhood in Atlanta was colored based on the intensity of the crime count/score, using the seaborn package. For data that was missing from either the ARC Shapefiles or the crime reports, the neighborhoods were intentionally left white. For example, “Airport” is technically a neighborhood on its own in Atlanta, but there were no reported crimes for it in the dataset. In all other cases, the darker colors indicate a higher intensity in crime count/score.
2019 Actual Data (Ground Truth)
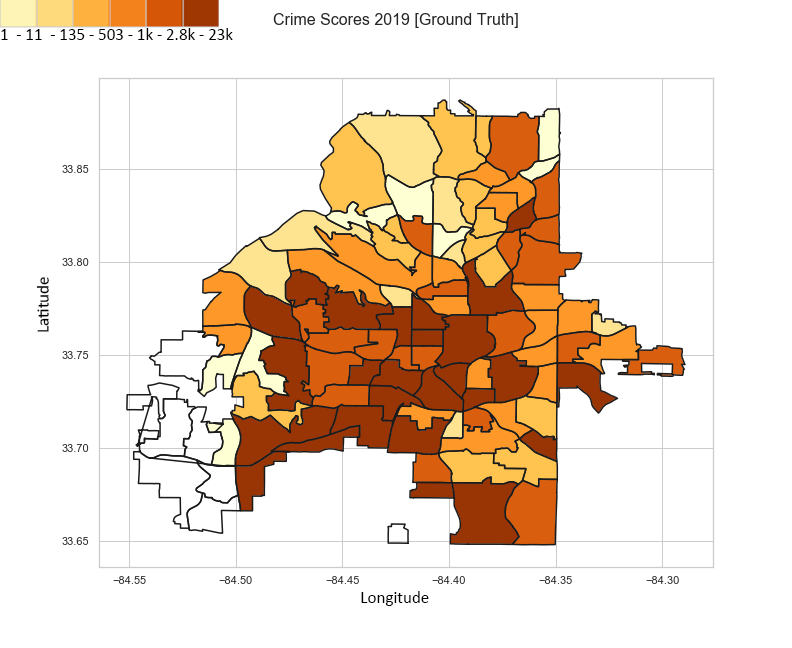 This image is a visualization of our ground truth data from the 2019 dataset.
This image is a visualization of our ground truth data from the 2019 dataset.
2019 Predicted Data using ML (Naive Bayes)
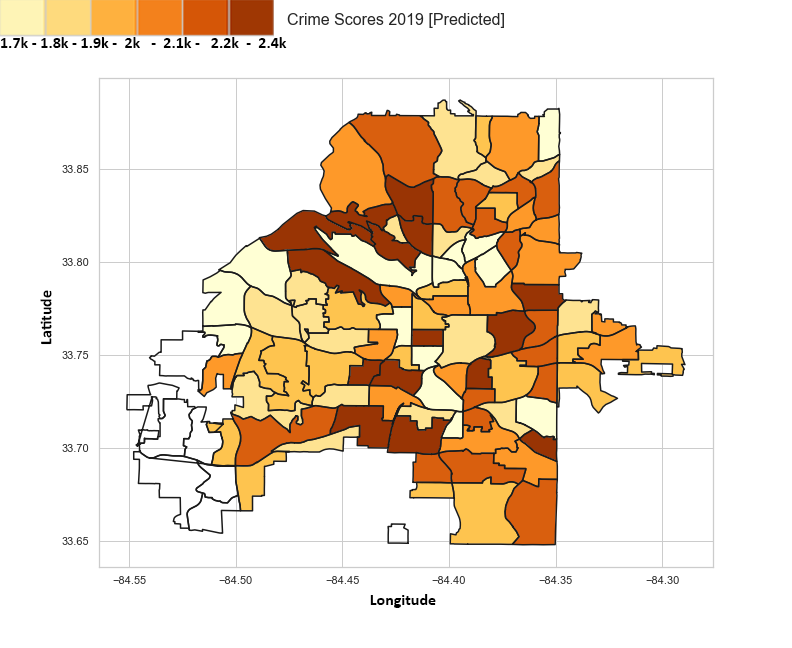
This image is our machine learning model’s predicted 2019 data. We found Naive Bayes to have the higher accuracy among our attempted methods.
Unsupervised Methods
Initially we wanted to explore our data more to understand if certain associations of crime category could be inferred from selected features. For unsupervised methods we conducted Dimensionality Reduction (PCA/LDA) and Clustering (KMeans, Mean Shift, and DBSCAN).
Dimensionality Reduction
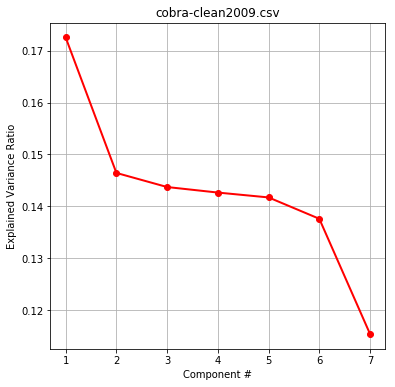
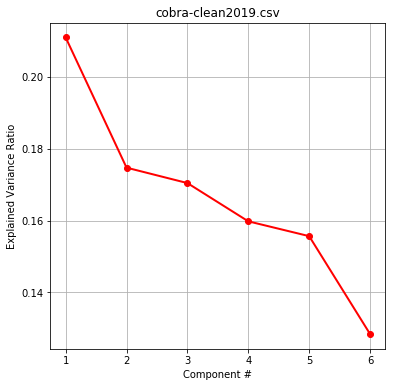
Within dimensionality reduction we were interested in if certain components/discriminants would contain high explained variance ratios. This would indicate to us which components (or features) may be of relative importance. LDA results were found to be less conclusive than PCA, and were hence not included. We decided to select the most relevant numerical features for our algorithms to include in PCA.
Features selected for PCA:
['Occur Date','Occur Time','Day of Week','Month','Day of Month','Year','Latitude','Longitude','Crime Category'] on
- Cleaned crime data for COBRA-2009-2018
- Cleaned crime data for COBRA-2019
Numerical features were scaled to unit variance of centered data before performing PCA.
You will notice cobra-clean2019.csv has less components due to['Year']being removed from features (as all data is from 2019).
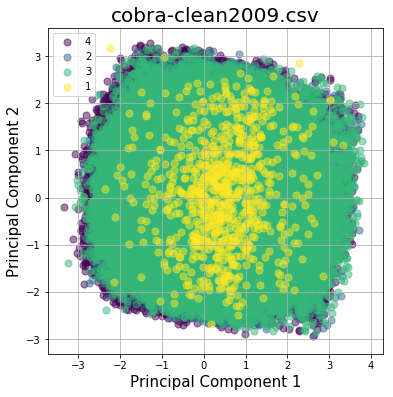
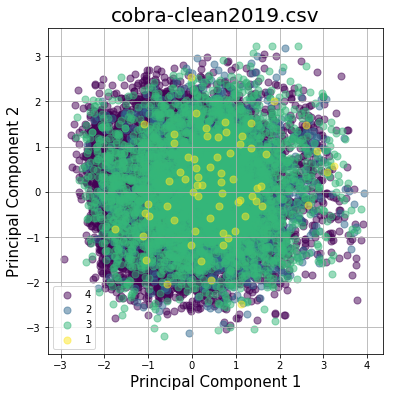
Scatter plots of the first two components show little separation between groups.
Exploring explained variance ratios per component reveal a similar relative margin between components. Therefore we need to maximize our feature inclusion, and are justified in regularizing our data.
Location-based Clustering
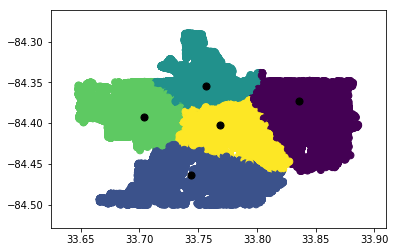
Our intial thoughts were to cluster by longitude and latitude to see if there was any uneven location distribution.
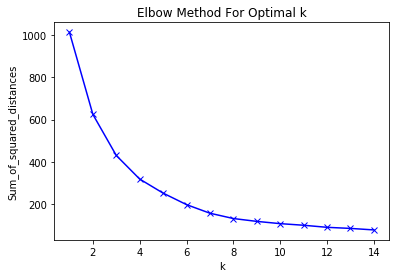
We utilized Elbow Method plots to determine optimal epsilon given min_samples for DBSCAN, and optimal K-value for KMeans.
Clusters were plotted separately and overlayed with crime categories to determine any location trends, yielding disparate results. DBSCAN followed a similar trend and did not yield much visual insight.
KMeans Location Results
Mean Shift Location Results

Multi-Feature KMeans Clustering With & Without PCA
As location-based clustering, and PCA on it’s own yielded little utility in our overall project goal, we then proceeded with multi-feature exploratory KMeans clustering.
Features included were consistent from the previous PCA method:
['Occur Date','Occur Time','Day of Week','Month','Day of Month','Year','Latitude','Longitude','Crime Category']
Initially KMeans was conducted on all normalized features, and all combinations of features were plotted and colored by associated cluster. Then in an attempt to further explore our data, we performed PCA prior to clustering. Each cluster was plotted and overlayed with colors corresponding to crime category (indexed from previous operations). However, as our results below indicate, this approach also yielded little insight.
Feature Generation for Supervised Methods
To include more features within our unsupervised approach we decided to generate five new features with KMeans for our supervised methods. This would hopefully increase the amount of information, and accuracy potentially achieved downstream.
First we normalized our data to a standard scaler, chose an optimal K-value from our Elbow Method, and fit our data to KMeans. New features composed of the Euclidean Distance of each point to all K centroids were appended to data for downstream supervised modeling.
Supervised Methods
Some initial preprocessing is done with the data before the entered into the model. We utilized the 2019 data for testing, and 2009-2018 data for training. This is the first time we use the Crime Score. We created this metric after obtaining domain knowledge of severity in crimes. Understanding the judicial system’s consequences for certain crimes, we were able to manufacture a crime score for each neighborhood to took the severity of the crime into account. This is unique part of our project that aims to help map the toughest crime hotspots to police officers.
Chosen Supervised Algorithms
- Decision Tree
- Random Forest
- Naive-Bayes Classifier
- Linear Regression
Based off of the location and time—specifically the neighorhood, day of the week, the month, and time in which the crime occurred—we are able to predict the most likely category of the crime and regress on the crime scores.
After our data was preprocessed, we built classification and regression methods using Decision Trees, Random Forest, Naive-Bayes and Linear Regression. For Linear Regression classification of crime categories, the closest category integer would be obtained from the predicted result (i.e., if the prediction is 3.25 then it becomes category 3).
We attempted to do Support Vector Machine and Logistic Regression models, but they took way too long and either had low performances or crashed the kernel. Because it led to unsatisfactory results, we removed them from our results section and chose to move forward.
While the baseline of the project was to examine the category and crime score results when given the setting of the crime, we also built separate results for the added features generated by KMeans. Four models were built per supervised algorithm, in which each model was a combination of classification/regression and data with features/data without features.
Metrics & Results
The metrics that were grabbed from the classification and regression models were the respective runtimes, accuracy/precision/recall metrics, and RMSE values.
Elapsed Times
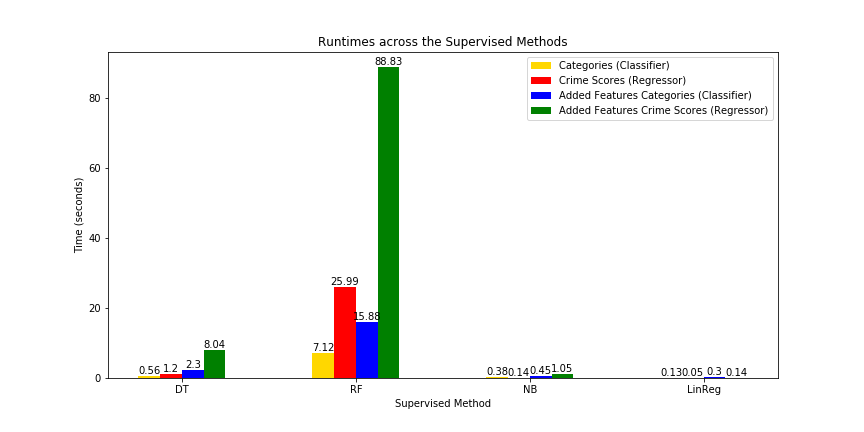
When it comes to time, Naive-Bayes and Linear Regression are the two quickest algorithms that we ran, whereas Random Forest ended up being the slowest across all its four models. The added features in particular were what contributed to Random Forest’s high runtimes, having up to three times the runtime of Random Forest without the features.
Accuracy, Precision, Recalls of Crime Categories
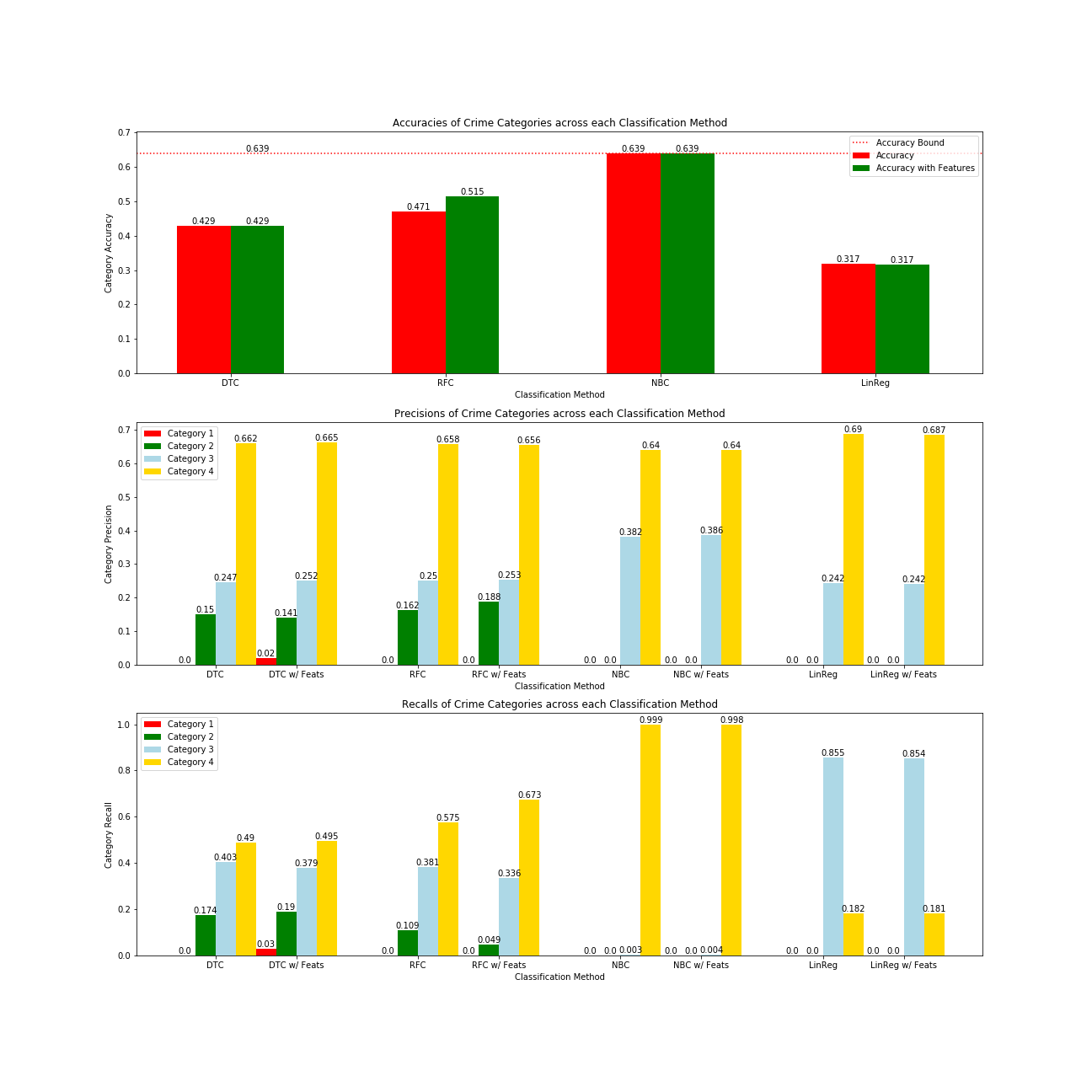
As for the accuracy metrics when classifying the crime category, Naive-Bayes Classifier ended up being at 0.639 for both of its models, and the only algorithm able to obtain an accuracy at least higher than the accuracy bound (0.639). The accuracy bound is calculated by classifying all data points as the most popular category in the test set, which ended up being Category 4, and obtaining the accuracy from there. However, the issue is that Naive Bayes classified almost all entry as Category 4 (the recalls are 0.999 without the five features and 0.998 with the features), which ended up having an issue with multi-labeled classification: it never predicted 1s or 2s, but only 3s and 4s.
Additionally, the Random Forest models ended up doing better with features than without, whereas all the other models had less consistent improvements. Despite this, Decision Trees had a much faster run and had relatively the same precision, which may seem to outperform the Random Forests when it comes to having an urgent need of prediction. Despite this, Random Forest still had accuracies of 0.471 without factoring the features and 0.515 with the new features, which may be low.
As for Linear Regressions, it has the poorest performance across all the models. Considering that each of the other models can be argued for being the preferred model, it was not worth considering running any regression model and rounding its values to fit a classification model.
Evaluation of the Models
Our preferred supervised method of choice for category classification is Random Forest since it had a more distributed range of choosing categories and improved when adding the features. That being said, Decision Trees aren’t that bad either, since it can give a close precision in a much quicker time.
As for crime scores, Linear Regression was the most useful since it had the quickest runtimes and lowest RMSE values of 42.62 for both of its models. There was virtually no other algorithm, out of the four, that could’ve been used.
The question of whether to add the clustering features or not still remains uncertain. It seems that for Random Forest it would be acceptable, though the other algorithms would do the same, if not better, without the features.
RMSE of Crime Scores
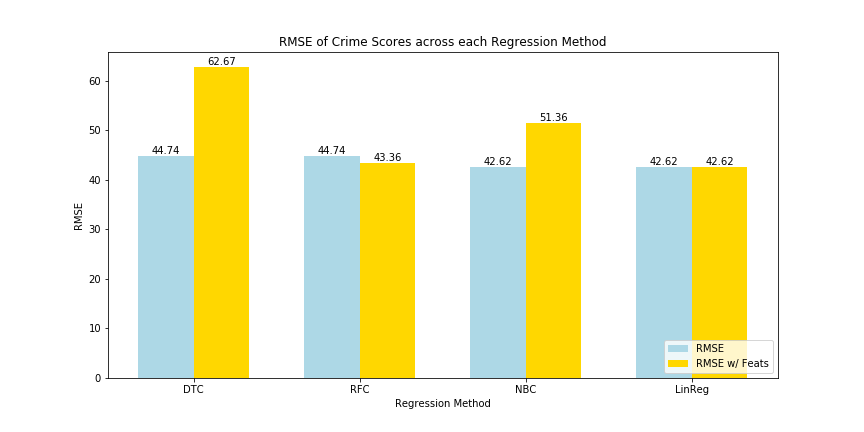
Lastly, the RMSE values showed that Linear Regression had the lowest error, when regressing the crime scores, and more importantly had no increase in its RMSE when adding the clustering features. And, because of its fast runtime, it would suggest that Linear Regression ought to be used for crime score estimations and less for crime category classification. The highest RMSE values were from Decision Trees, though the difference between the others, even when accounting for the added features, might not necessarily be that much.
Discussion
True crime prediction entails a complex set of variables that may not be publicly available for intrepid data scientists. Socioeconomic factors may be difficult to aggregate, while psychological motivators are highly abstract. Identification of crime hotspots allows law enforcement agencies to allocate police routes and other crime inhibiting factors, such as CCTV cameras, lights or neighborhood watches, more effectively [3]. Crime inciters, such as gang territories, bars, and construction sites can be monitored more frequently.
We evaluated our approach using accuracy, precision, and recall for classification of categories. In regression of crime scores, our metric is RMSE.
Conclusion
Major Achievement
Our major achievement was our supervised model using crime score, and our ability to understand more about Atlanta crimes and how one can predict the occurrence. The unsupervised algorithms were also useful in examining the intensity of each neighborhood.
Future work
Without question, our methodology could be improved. Given more time and resources, we would plan to merge our dataset with other datasets regarding Atlanta’s location specifics. Giving neighborhoods more features and more variability would only help our model learn and raise our accuracy. Another thing we may consider would be implementing similar prediction using deep learning neural networks.
The approach of splitting areas into grids and calculating within those regions (while fine-tuning the grid-size) could be integrated into our approach, whether “globally” -within the whole city- or “locally” -within each neighborhood- for greater effect. Addition of Twitter datafeed into the Machine Learning model has been proven to increase accuracy for the grid-based approach, and would be interesting to see the effects of on the afore-mentioned hybrid.
Although we had access to 300,000+ rows of data, access to more data/features would make our model more robust.
References
[1] Schiller, Andrew. “Atlanta, GA Crime Rates & Statistics.” NeighborhoodScout. NeighborhoodScout, 10 June 2019. Web. 30 Sept. 2019.
[2] Mcclendon, Lawrence, and Natarajan Meghanathan. “Using Machine Learning Algorithms to Analyze Crime Data.” Machine Learning and Applications: An International Journal 2.1 (2015): 1-12. Print.
[3] Lin, Ying-Lung, Meng-Feng Yen, and Liang-Chih Yu. “Grid-Based Crime Prediction Using Geographical Features.” ISPRS International Journal of Geo-Information 7.8 (2018): 298. Print.
[4] Kim, Suhong, Param Joshi, Parminder Singh Kalsi, and Pooya Taheri. “Crime Analysis Through Machine Learning.” 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON) (2018): n. pag. Print.
[5] Bappee, Fateha Khanam, Amílcar Soares Júnior, and Stan Matwin. “Predicting Crime Using Spatial Features.” Advances in Artificial Intelligence Lecture Notes in Computer Science (2018): 367-73. Print.
Tech Stack Utilized: SciKit Learn, Seaborn, Matplotlib, Pandas, Numpy, Jupyter, Python, Bash.
Contributions from each team member:
- Gabriel Leventhal-Douglas: Unsupervised learning and GitHub pages
- Abdurrahmane Rikli: Unsupervised learning and visualizations
- Sanjeev Prasada: Preprocessing and GitHub pages
- Aayush Dubey: Supervised learning and hypertuning parameters for model
- Kevin Tynes: Unsupervised learning and preprocessing
Although members led different portions of our project, we all believe that our individual contributions were equivalent.